前言
票真的难抢,决定自己写一个登陆抢票的
经典老三样
打开charles
打开隐私模式的firefox登陆抢票网站
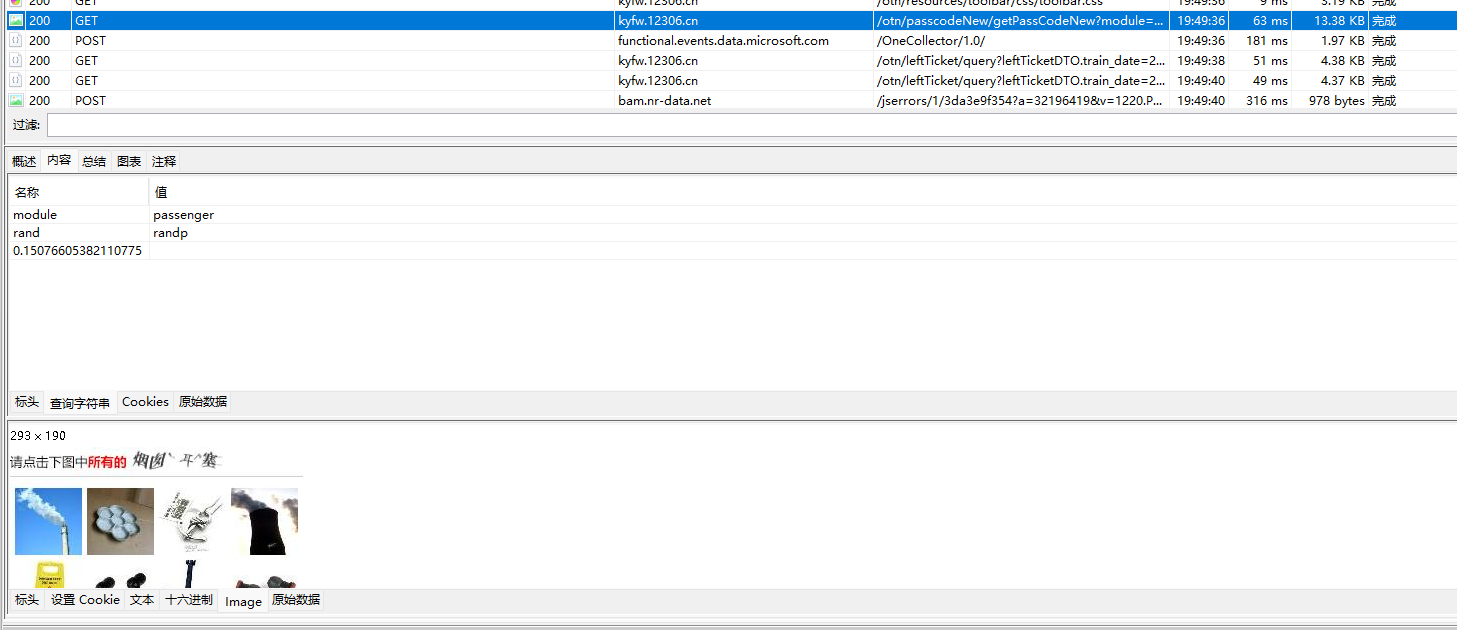
 我决定走扫码登陆,所以这里就直接点扫码,然后找到对应code的图片网址
我决定走扫码登陆,所以这里就直接点扫码,然后找到对应code的图片网址

 随便写个测试一下
随便写个测试一下
1
2
3
4
5
6
7
8
9
10
11
|
import requests
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:107.0) Gecko/20100101 Firefox/107.0",
}
host = "kyfw.12306.cn"
data = {
"appid":"otn"
}
position = "/passport/web/create-qr64"
res = requests.post("https://{}{}".format(host,position),headers=header,data=data,verify=False)
|
看charles抓包结果
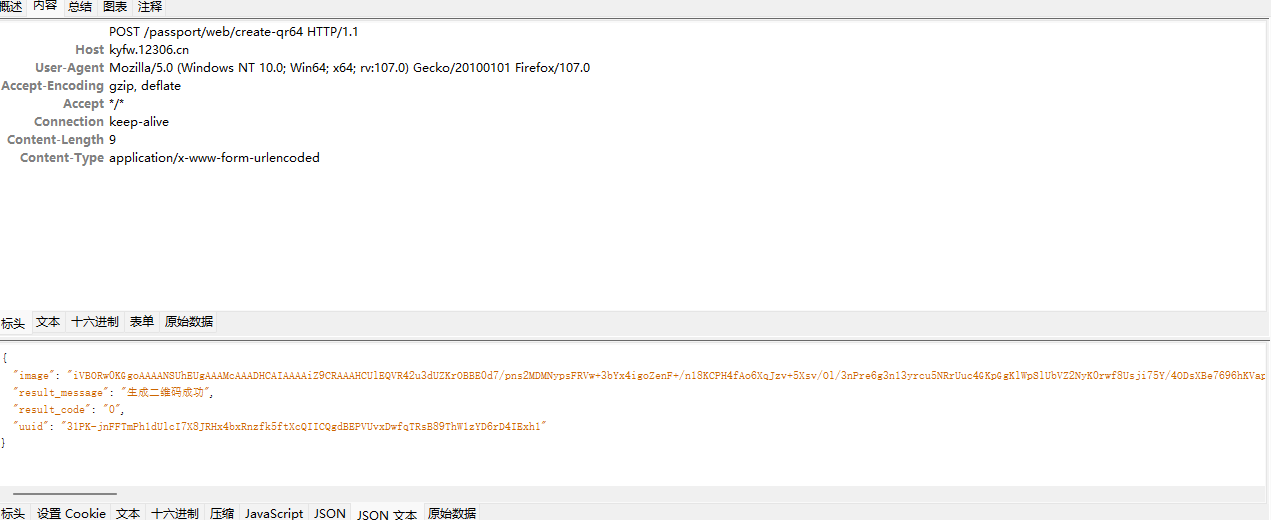
好像不需要什么其他请求和参数,然后试一下保存扫码+查询结果,查询qrcode是否被扫描qrcode接口是这个
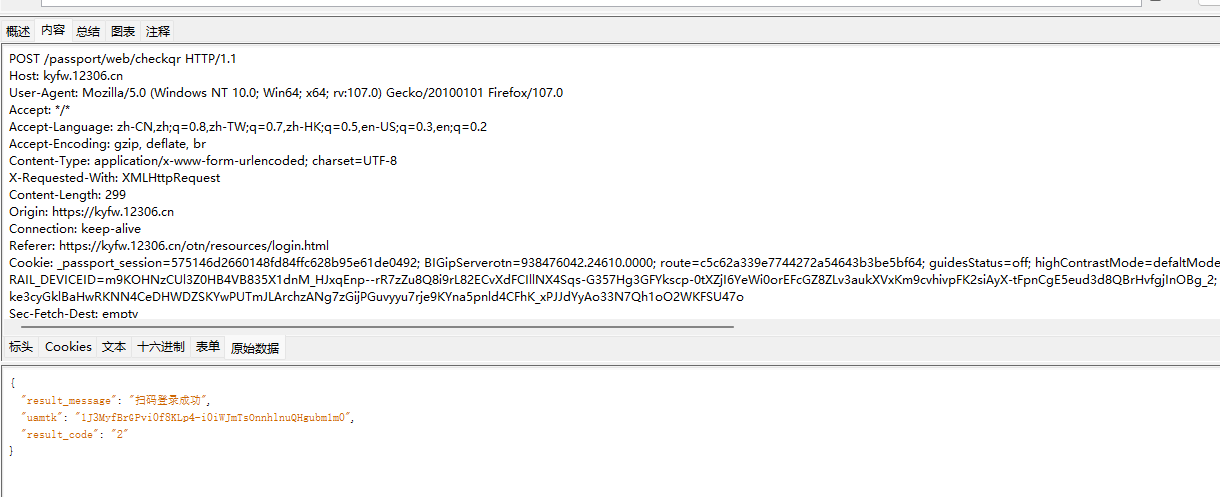
照着写吧
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
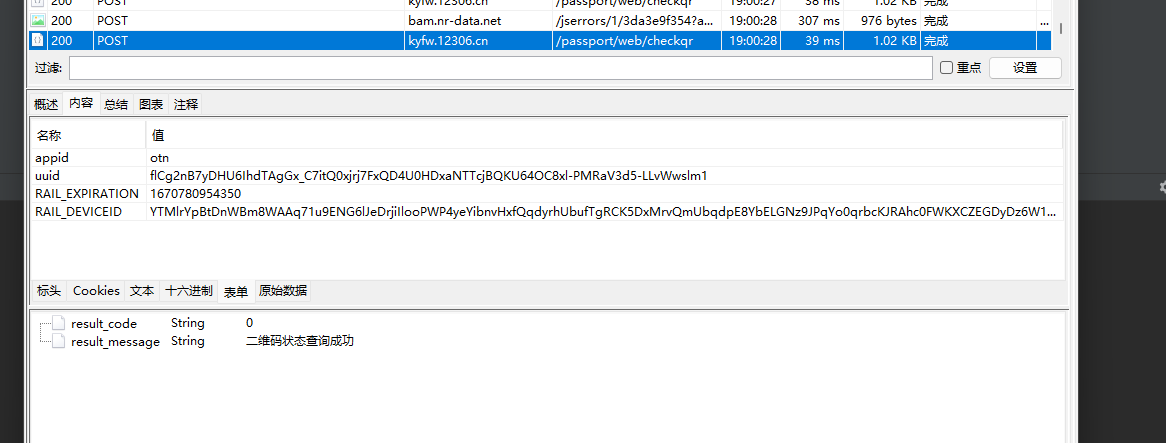
resultDict = json.loads(res.text)
uuid = resultDict["uuid"]
with open("./qrcode.png","wb") as f:
f.write(base64.b64decode(resultDict["image"].encode()))
f.close()
position = "/passport/web/checkqr"
data["uuid"] = uuid
ifBeenScan = False
while True:
res = session.post("https://{}{}".format(host,position),headers=header,data=data,verify=False)
result = json.loads(res.text)
result_code = result["result_code"]
if result_code == "2":
print(result_message)
session.cookies["uamtk"] = result["uamtk"]
break
else:
time.sleep(10)
print("请扫码")
postion = "/otn/login/userLogin"
session.post("https://{}{}".format(host,postion),headers=header,data=data,verify=False)
|
写完以后运行,成功扫码了,但是没有返回扫码成功
尝试调低了timesleep时间也没有返回成功扫码
是不是cookie不全呢
没办法只能一个个找cookie了
对照找找,我缺的cookie很多,原请求如下
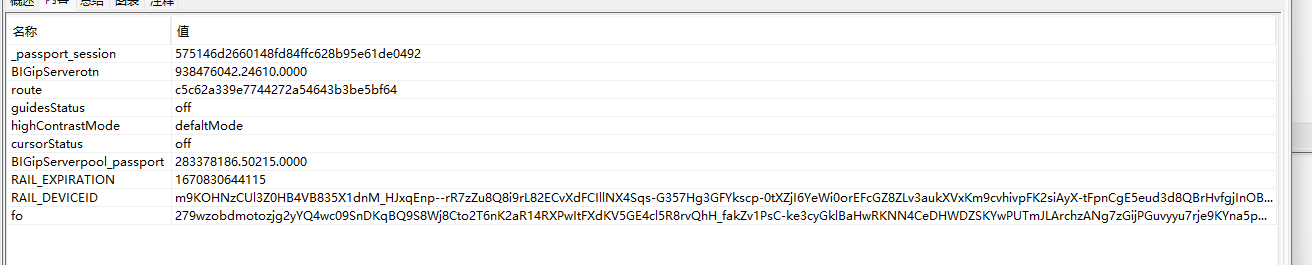
我的请求如下
 翻了一下能找到的是这些
翻了一下能找到的是这些
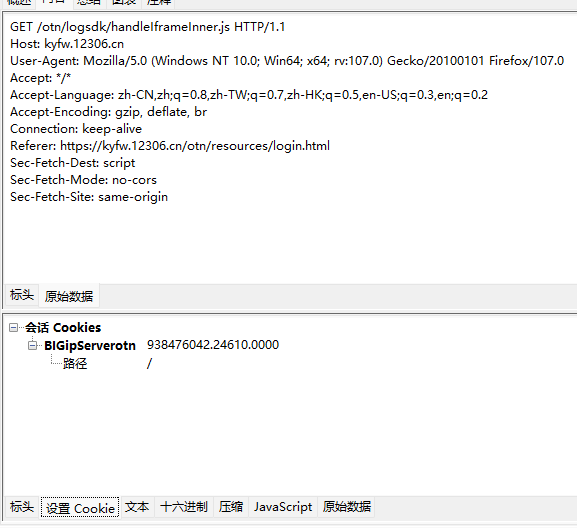
直接请求试试

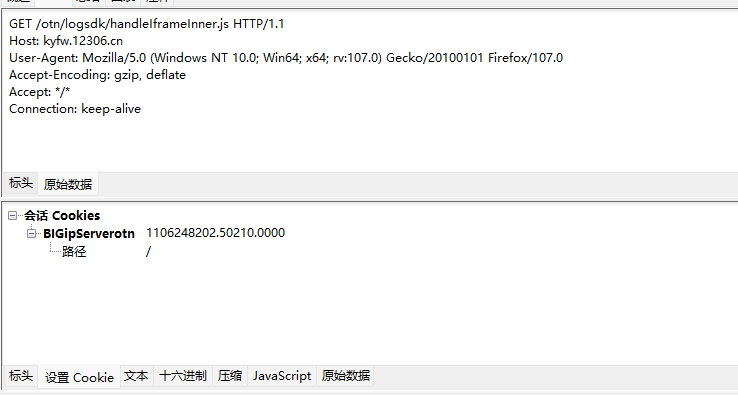 可以得到,解决了一个
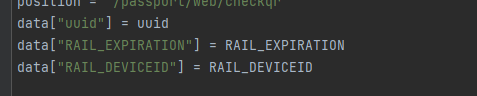
这个地方明显是返回的rail_expiration和rail_deviceid,但是这里是个callback,必须得看看请求参数
可以得到,解决了一个
这个地方明显是返回的rail_expiration和rail_deviceid,但是这里是个callback,必须得看看请求参数
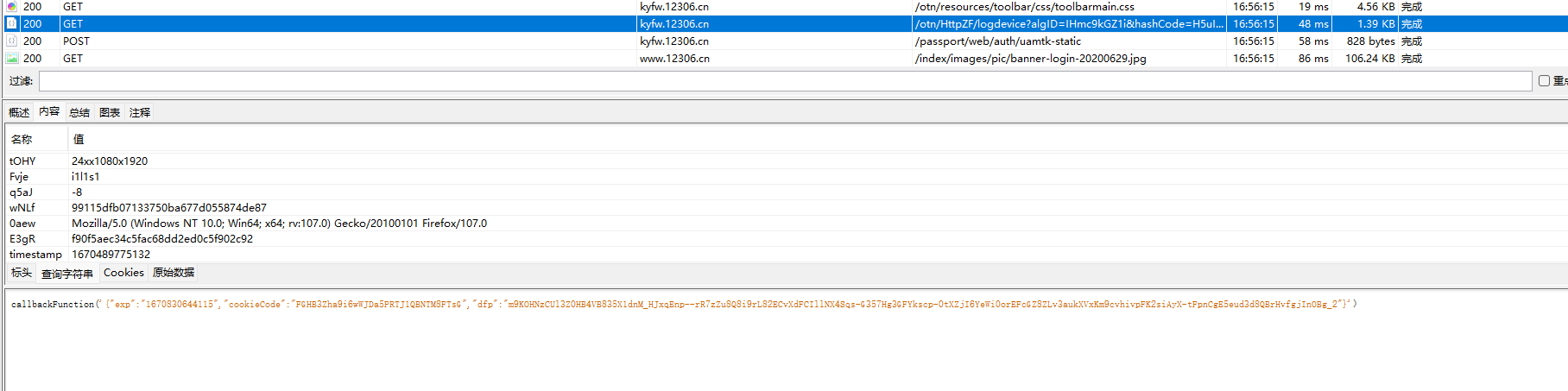
龟龟,你杀了我算了
 还有fo
还有fo
转换一下思路
首先尝试一下能正确获取二维码状态的cookie
直接重发
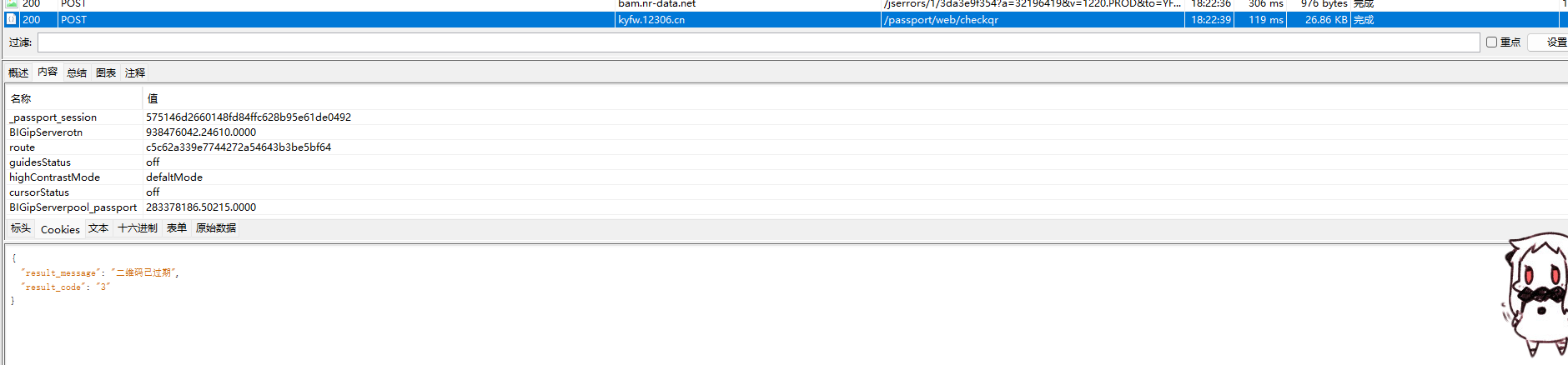 可以获取结果,然后试试删掉几个
删掉fo
可以获取结果,然后试试删掉几个
删掉fo
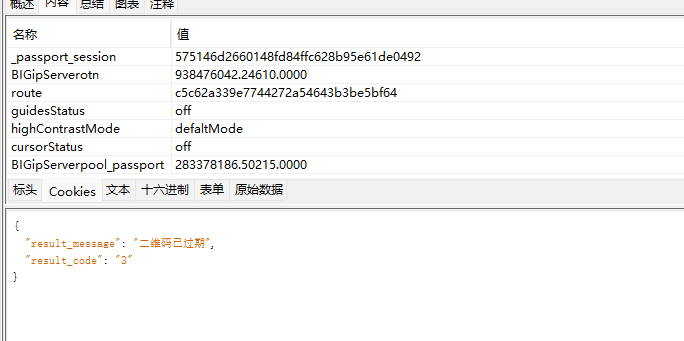 可以返回
删掉两个rail cookie
可以返回
删掉两个rail cookie
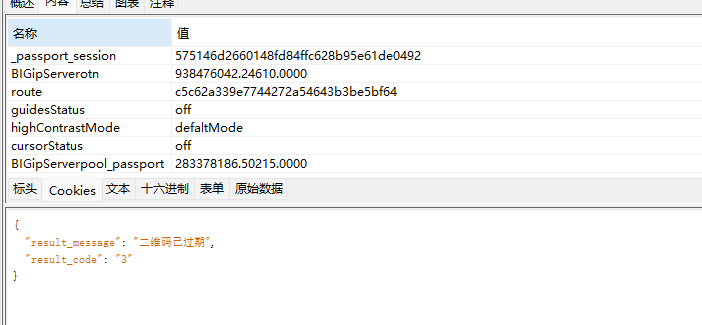 还是可以,怪事,试试直接删完
还是可以,怪事,试试直接删完
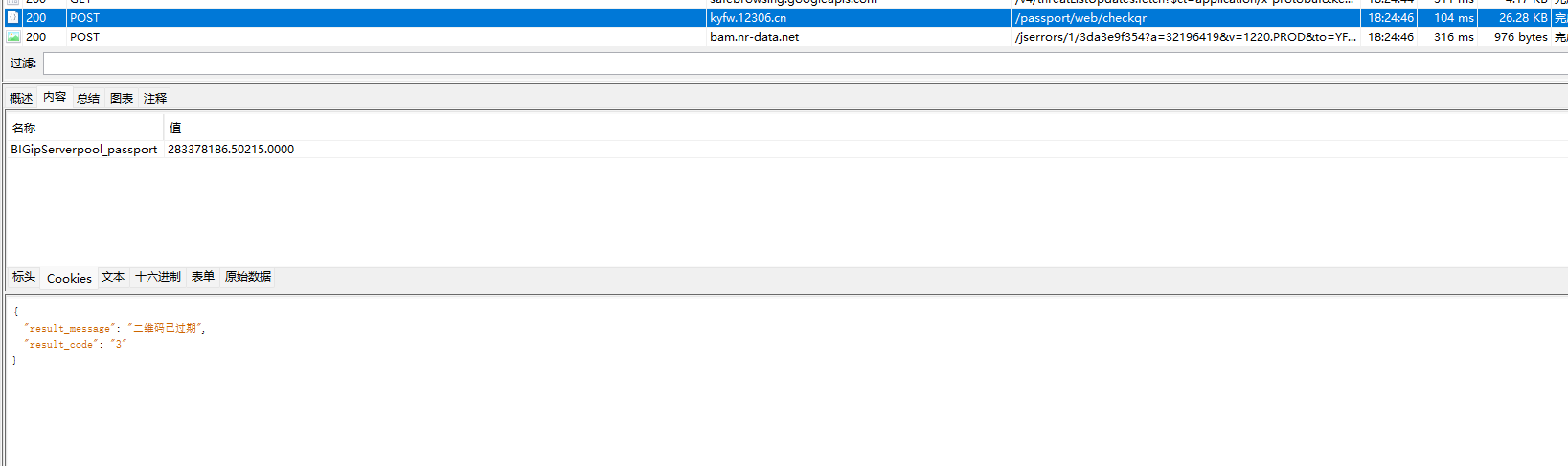 好吧看来行不通,先重新申请一个二维码试试cookie
好吧看来行不通,先重新申请一个二维码试试cookie
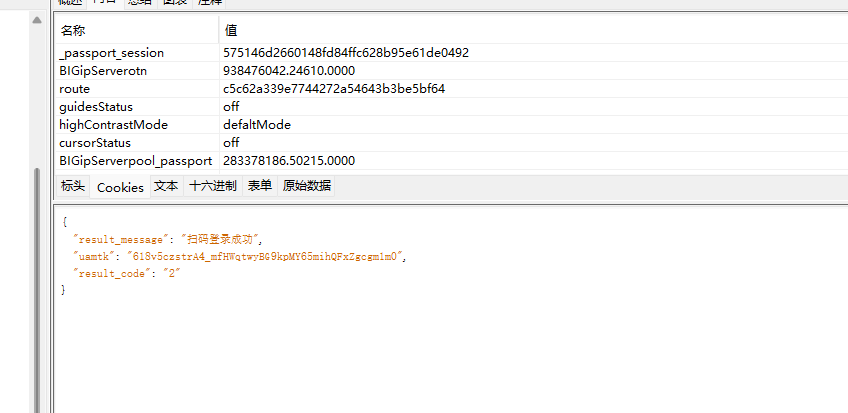 现在可以了,开始删cookie
删掉rail
现在可以了,开始删cookie
删掉rail
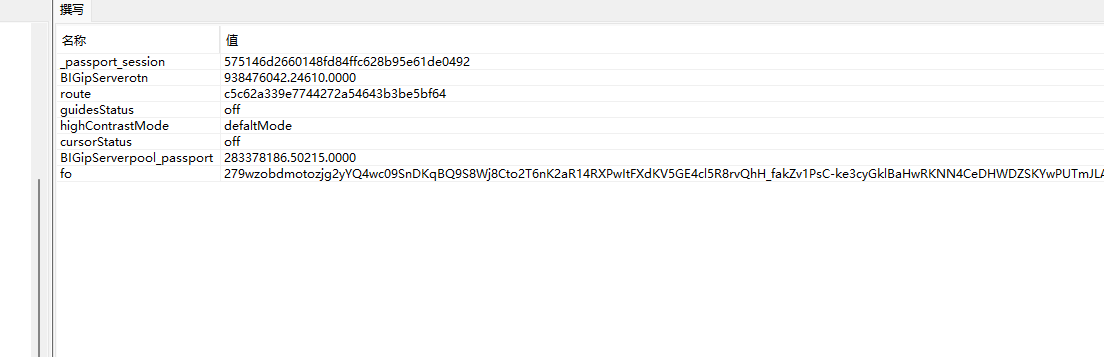 全删!
全删!
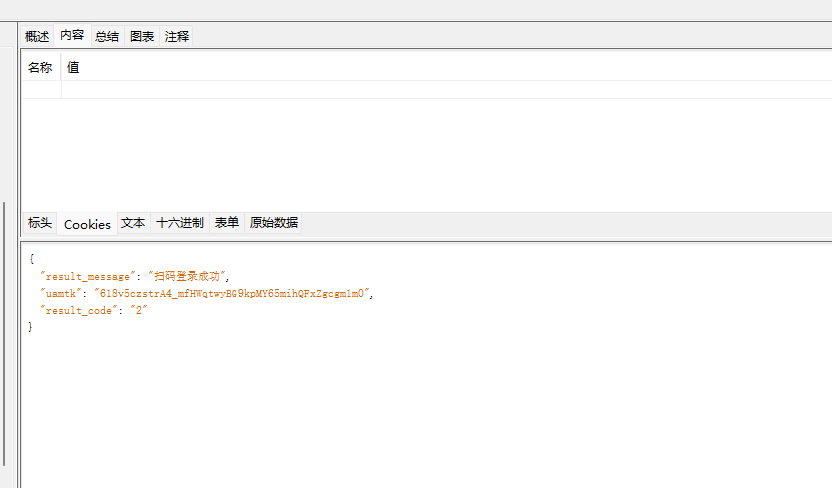 我*,问题出在请求头上了
最后定位了一下,问题还是出在了rail没有在表单里提交
以下证明
我*,问题出在请求头上了
最后定位了一下,问题还是出在了rail没有在表单里提交
以下证明
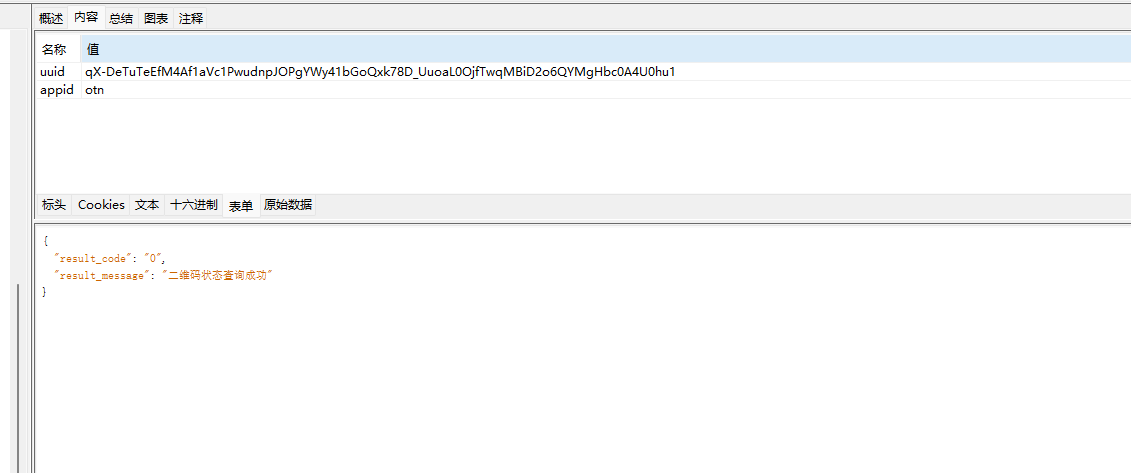
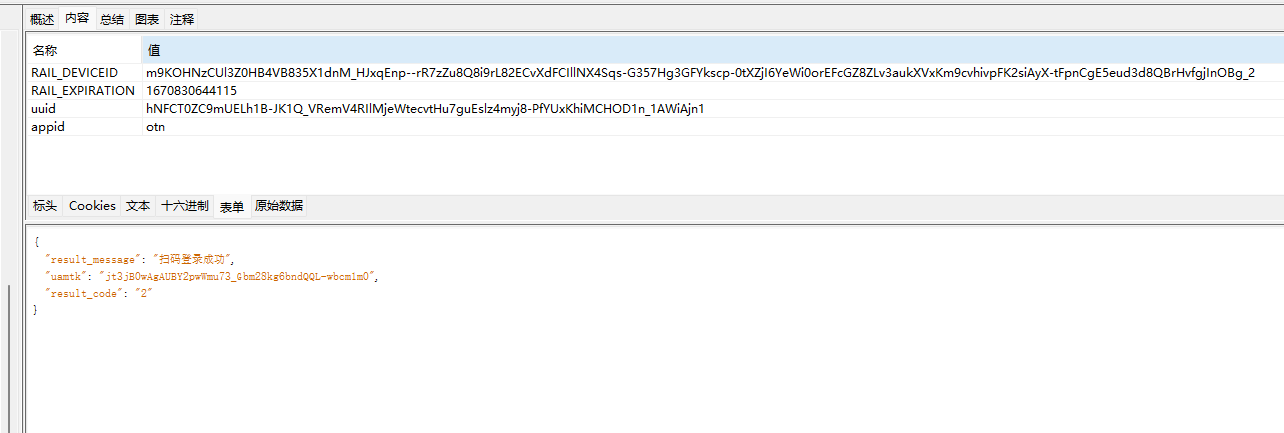 那问题就变为了如何获取rail的值
刚才定位到
那问题就变为了如何获取rail的值
刚才定位到
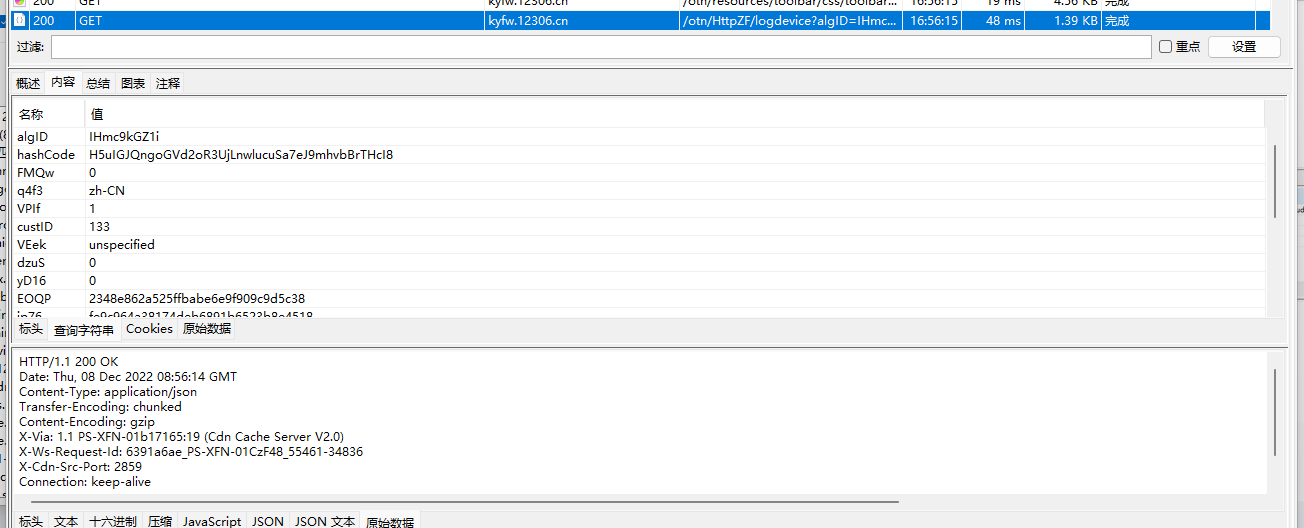
这个请求
把url删到只剩这个
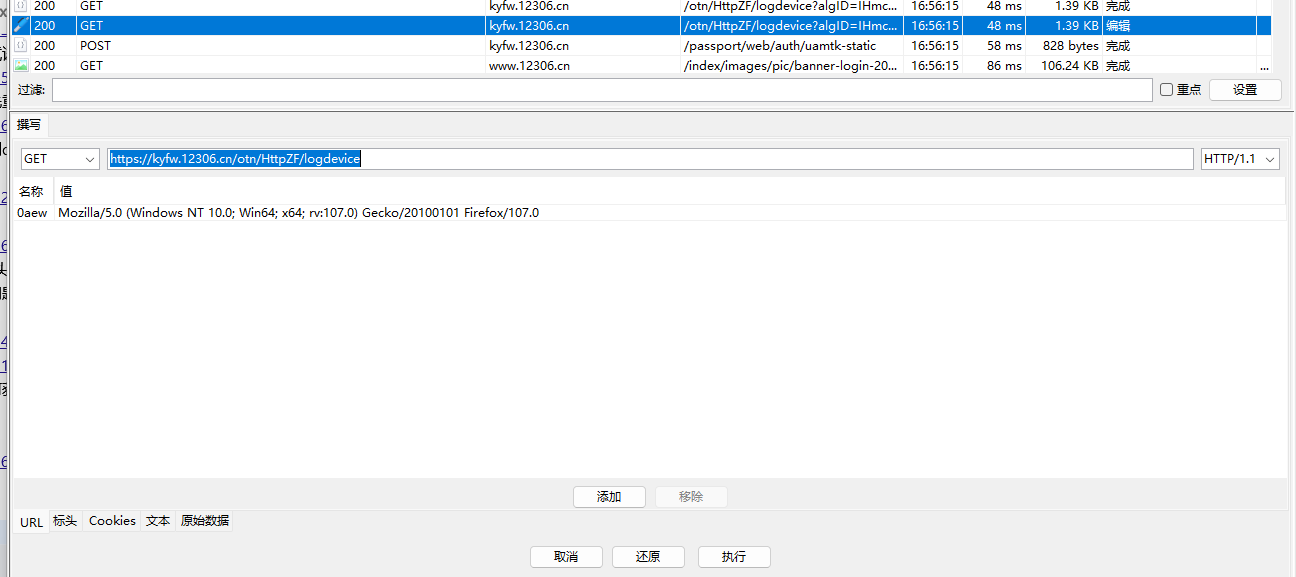 成功返回了
现在来试试python代码实现
成功返回了
现在来试试python代码实现
1
2
3
4
5
|
params = {
"0aew":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:107.0) Gecko/20100101 Firefox/107.0"
}
position = "/otn/HttpZF/logdevice"
res = session.get("https://{}{}".format(host,position),params=params,headers=header,verify=False)
|
我多说拿下了你是不是尔龙辣?
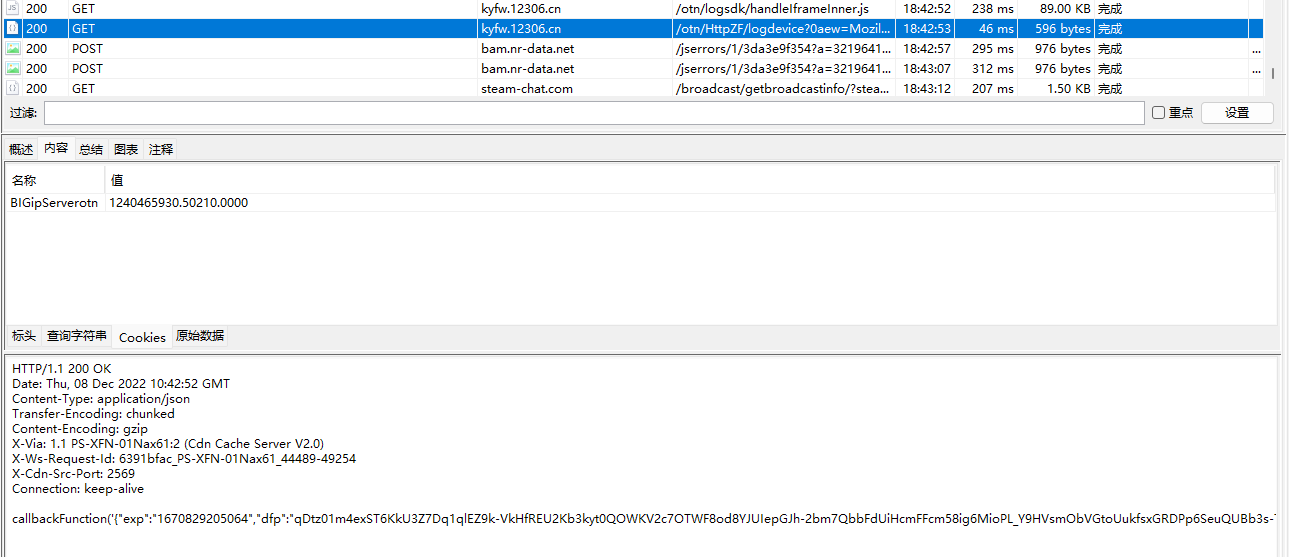 返回的值是json string
返回的值是json string
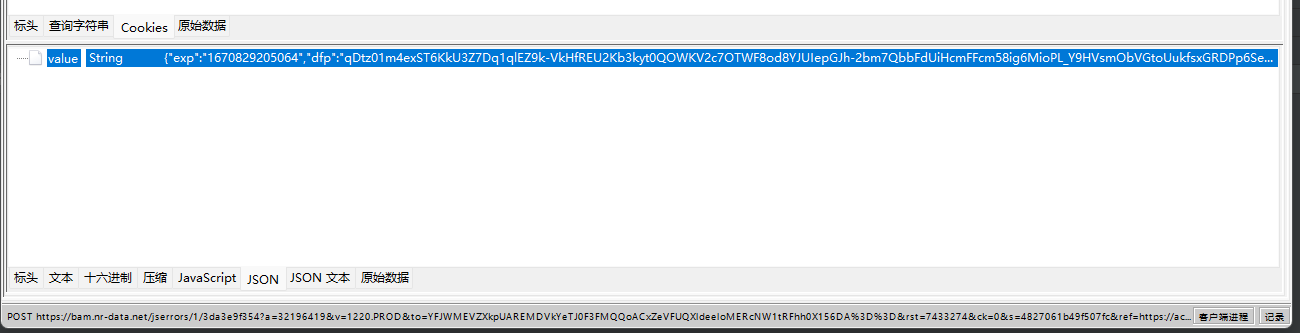 处理一下
处理一下
1
2
3
4
|
RAIL_EXPIRATION = json.loads(res.text)["exp"]
RAIL_DEVICEID = json.loads(res.text)["dfp"]
session.cookies.set("RAIL_EXPIRATION",RAIL_EXPIRATION)
session.cookies.set("RAIL_DEVICEID",RAIL_DEVICEID)
|
报错了,不过小问题啦
 把这个callback处理一下就行
把这个callback处理一下就行
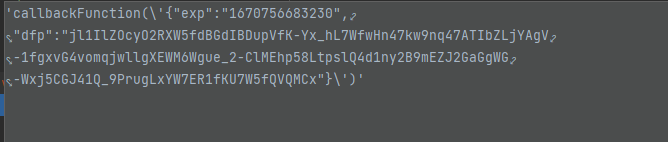
1
2
3
4
5
|
result = json.loads(res.text).strip("callbackFunction(").strip(")")
RAIL_EXPIRATION = result["exp"]
RAIL_DEVICEID = result["dfp"]
session.cookies.set("RAIL_EXPIRATION",RAIL_EXPIRATION)
session.cookies.set("RAIL_DEVICEID",RAIL_DEVICEID)
|
自信运行
我带你们打
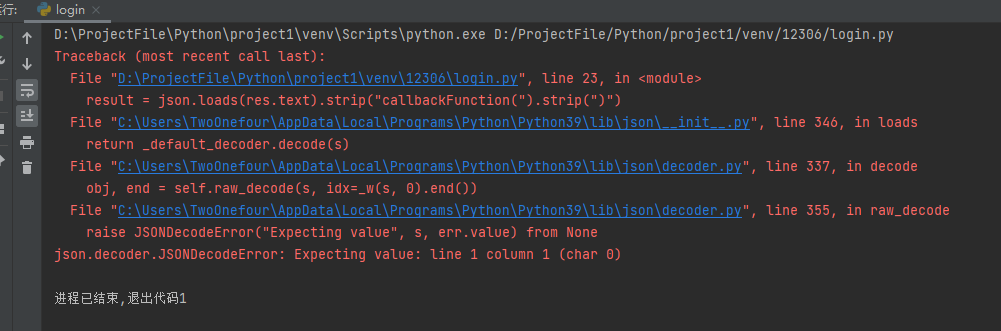 乐,写错了
乐,写错了
1
2
3
4
5
|
result = json.loads(res.text.strip("callbackFunction(").strip(")"))
RAIL_EXPIRATION = result["exp"]
RAIL_DEVICEID = result["dfp"]
session.cookies.set("RAIL_EXPIRATION",RAIL_EXPIRATION)
session.cookies.set("RAIL_DEVICEID",RAIL_DEVICEID)
|
自信运行
还是报错,那应该是这个反斜杠的锅,再去掉反斜杠
1
|
res.text.strip(r"callbackFunction('\\").strip(")").strip(res.text.strip(r"callbackFunction('\\").strip(r")")[-1])
|
操作有点傻了,但是能用就行
1
|
res.text.strip(r"callbackFunction('\\").strip(")")[:-1]
|
改了一下 ,应该可以了
看一下cookie
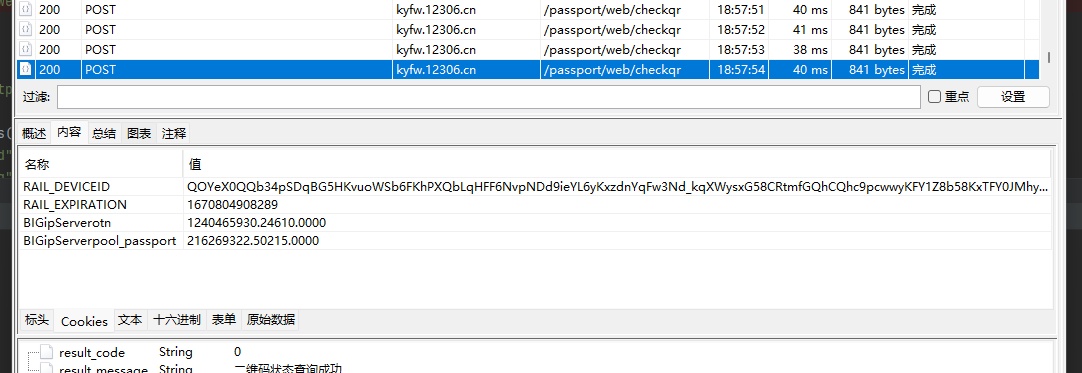 有了
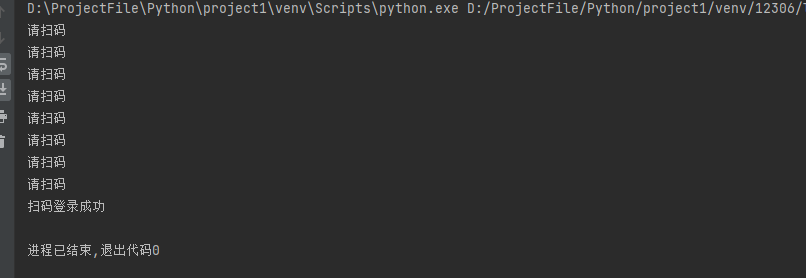
现在扫码
还是不行,忘记加表单请求了好像
有了
现在扫码
还是不行,忘记加表单请求了好像
加上去
 准备拿下
准备拿下
 好的翻车了
我尝试了交换以前的device id,也是可以的,那应该是请求头被识别出来了
判断了一下应该是同源请求
最后复制上请求头还不行,草
我觉得是表单顺序的问题,调了一下
还是不行
好的翻车了
我尝试了交换以前的device id,也是可以的,那应该是请求头被识别出来了
判断了一下应该是同源请求
最后复制上请求头还不行,草
我觉得是表单顺序的问题,调了一下
还是不行
只能是deviceid生成不正确了
目前是直接把整个复制过来加进去,我目前把timestamp改成1000,扫码以后deviceID明显过期了
不清楚以后这些参数会不会过期
 现在用cookie登陆
登陆只需要一个cookie
现在用cookie登陆
登陆只需要一个cookie
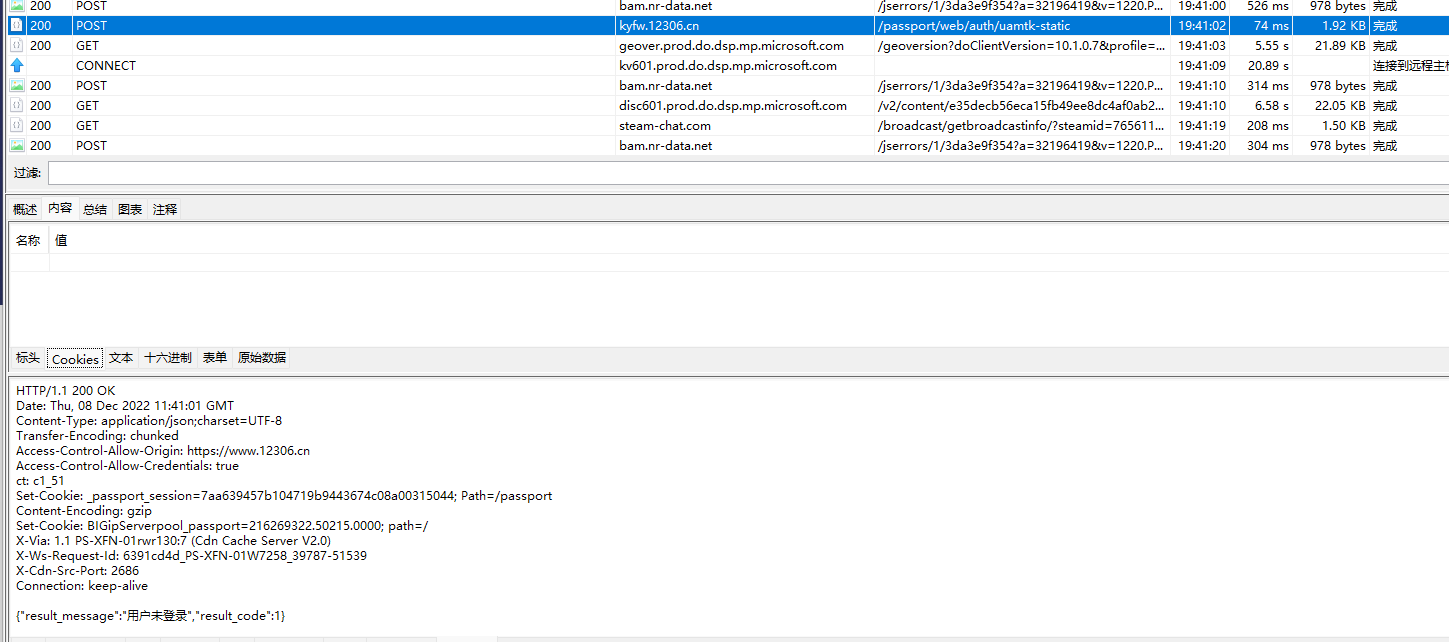
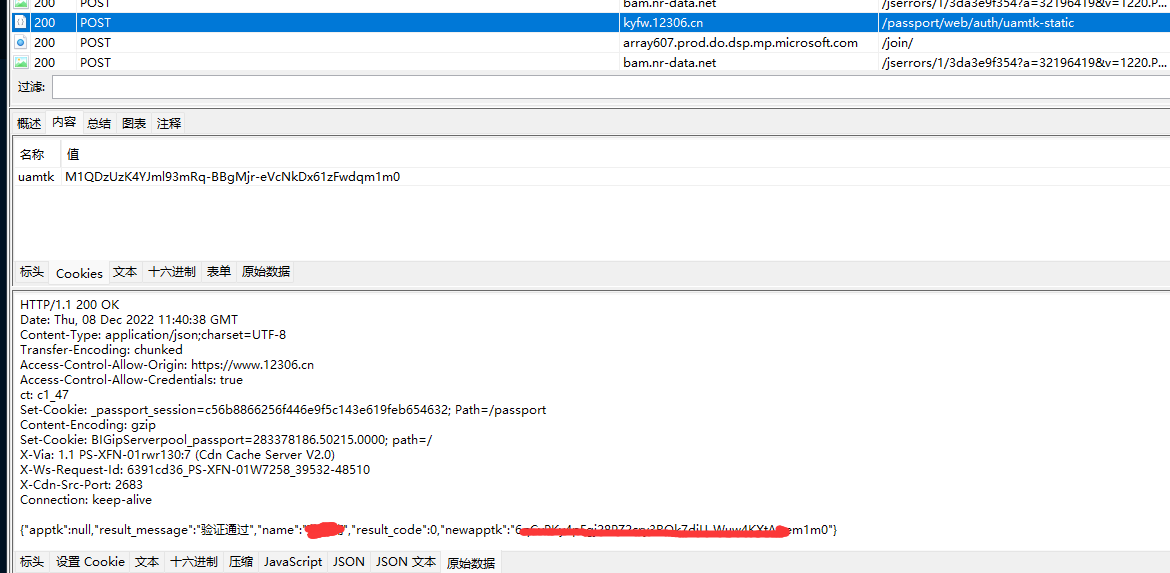
就是刚才得到的uamtk,post到接口就行
1
2
3
4
5
|
postion = "/passport/web/auth/uamtk-static"
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:107.0) Gecko/20100101 Firefox/107.0"
}
session.post("https://{}{}".format(host,postion),headers=header,data=data,verify=False)
|
很难不成功
然后就是我最喜欢的买票接口啦,随便点一个下单看看接口
先查询
查询
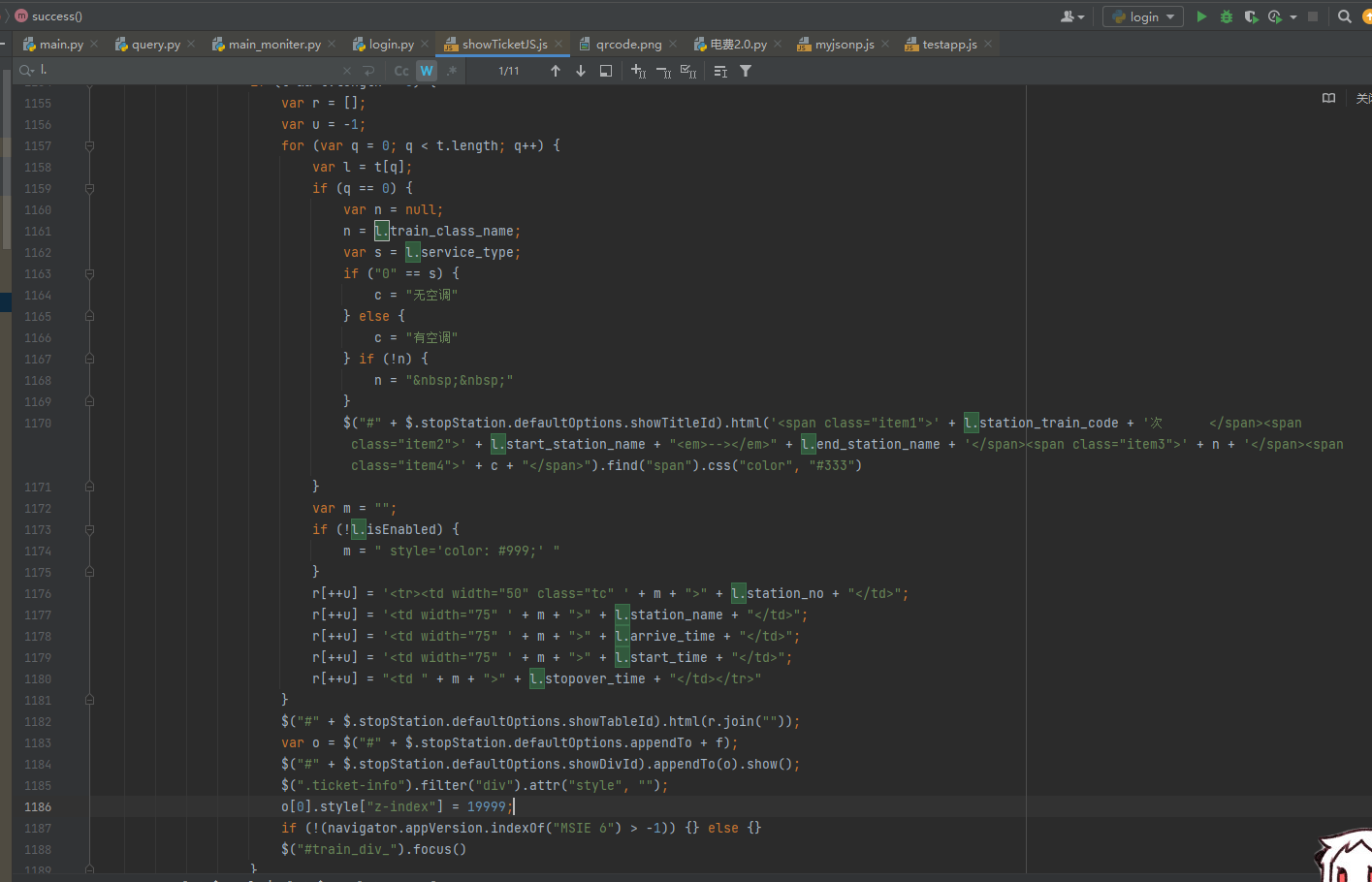
 这里具体思路就是html了,直接找xpath对应元素返回就行
我定位到了显示车票的ajax请求
这里具体思路就是html了,直接找xpath对应元素返回就行
我定位到了显示车票的ajax请求
 下断点到这里l的定义,看看他如何解析的,去反向推
但是这太耗费精力了,不如直接在返回的数据上下功夫
我分析了一下数据是这样的
如果是G开头的高铁,那么他会在第16条横线倒着来
比如
下断点到这里l的定义,看看他如何解析的,去反向推
但是这太耗费精力了,不如直接在返回的数据上下功夫
我分析了一下数据是这样的
如果是G开头的高铁,那么他会在第16条横线倒着来
比如
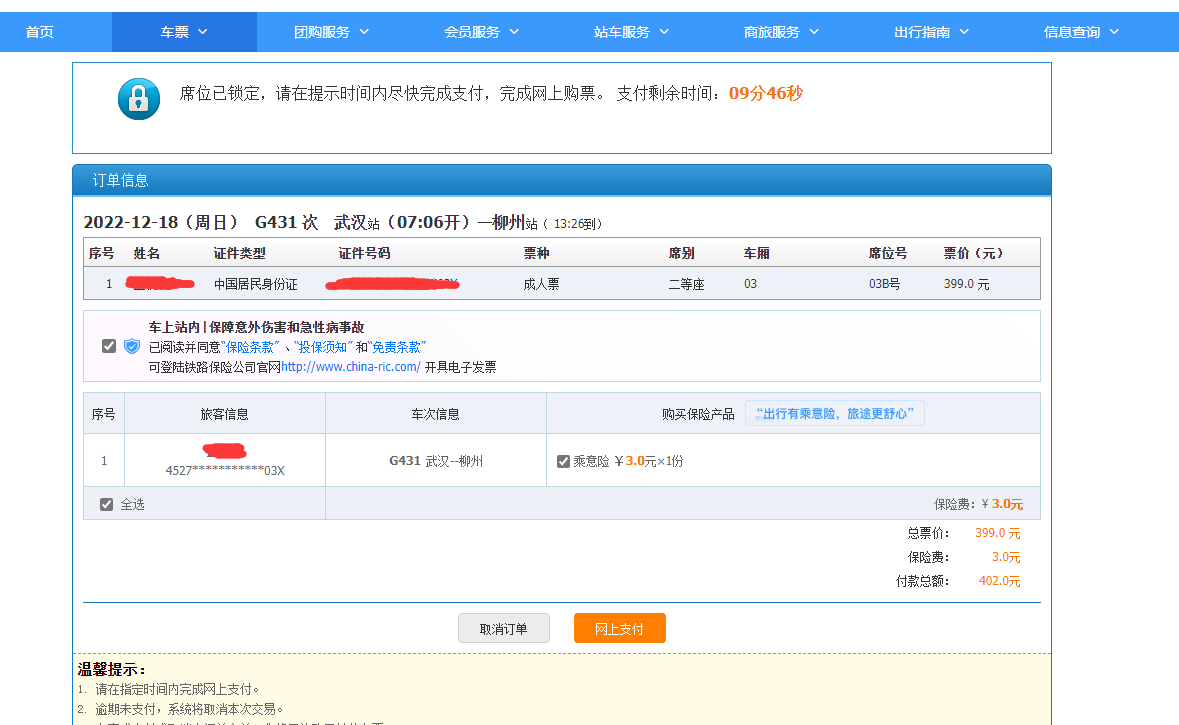 第2条
Z285
他的数据在这里
第2条
Z285
他的数据在这里
 打开
打开
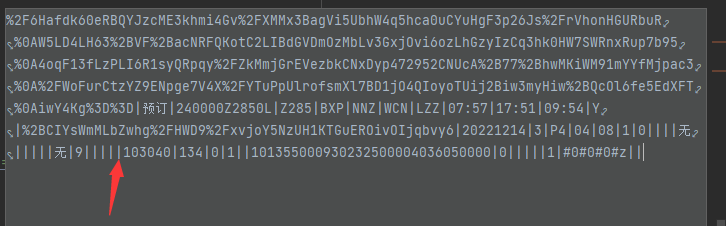 很明显从红色箭头所指开始数
第一个是软卧一等座,对应空
第二个是动卧,对应空
第三个是硬卧二等座,对应空
第四个是软座,对应空
第五个是硬座,对应9
第六个是无座,对应空
同理高铁也是倒着来
很明显从红色箭头所指开始数
第一个是软卧一等座,对应空
第二个是动卧,对应空
第三个是硬卧二等座,对应空
第四个是软座,对应空
第五个是硬座,对应9
第六个是无座,对应空
同理高铁也是倒着来
 这个20,有,有就很明显了
我们这里很穷,只监控硬座和二等座就可以了
我们要获取的数据是,列车的开头的起始时间,到站时间,持续时间,是否有座
那么思路就是,对返回的数据进行迭代,然后分割字符串获取数据
这个20,有,有就很明显了
我们这里很穷,只监控硬座和二等座就可以了
我们要获取的数据是,列车的开头的起始时间,到站时间,持续时间,是否有座
那么思路就是,对返回的数据进行迭代,然后分割字符串获取数据
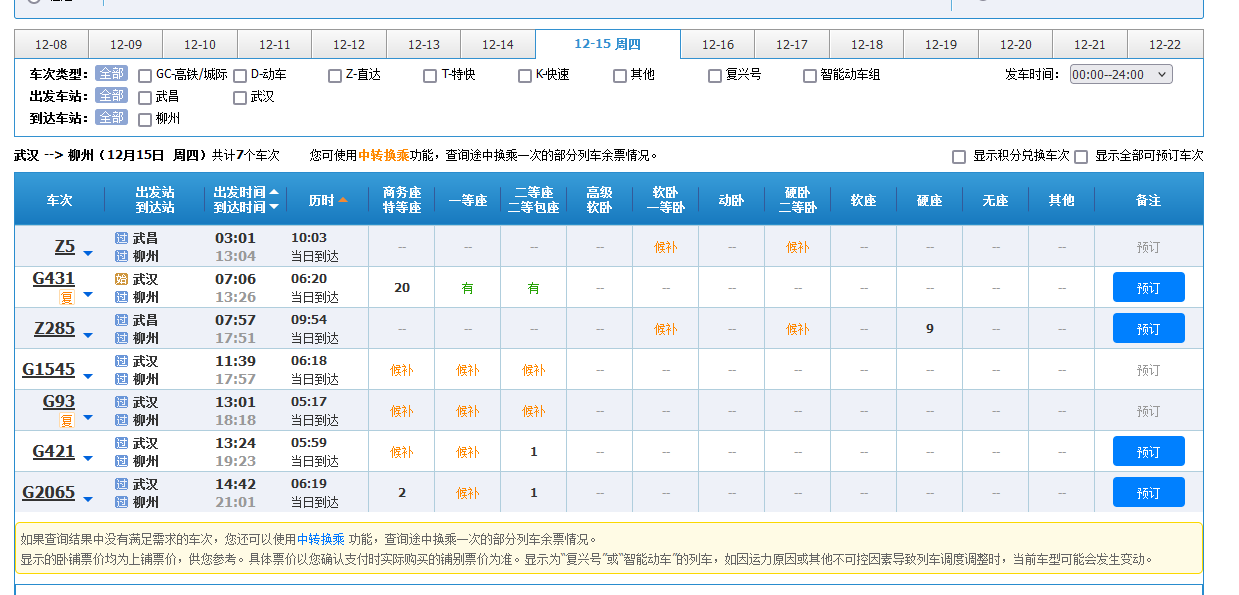 记一下数据,索引分别为
3对应列车号,
8对应起始时间
9为结束时间
10为持续时间
-17为第一个框
-18为第二个框
类推
记一下数据,索引分别为
3对应列车号,
8对应起始时间
9为结束时间
10为持续时间
-17为第一个框
-18为第二个框
类推
验证
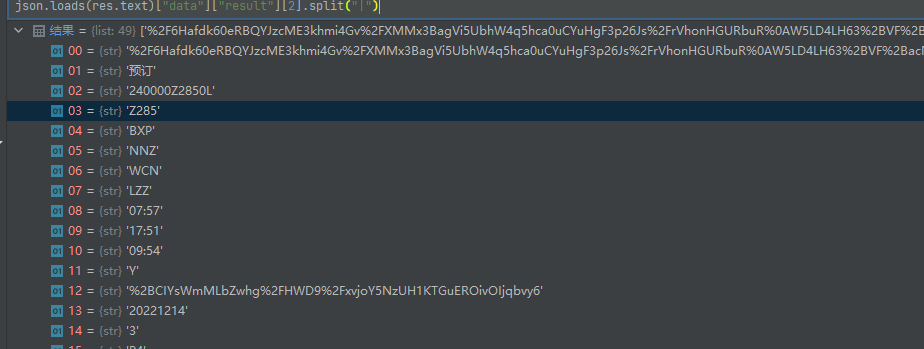
下单
 到这里就不会了,乌乌,弃坑
到这里就不会了,乌乌,弃坑