前言闲话
最近想看漫画,想起来以前有个kindle很好用,但找不到了。然后花65买了一个低配kindle,确实挺好用,看完了芙莉莲10卷漫画和我心危135话。
但看pdf不行,于是又花了188买了个 300ppi 的 kindle paperwhite 3,这下能看清楚pdf了,但实际上我还是用来看漫画,而且看漫画体验没什么区别,这个新的kindle还更重了。
话虽如此,我有两个kindle也没用,就把65块买的kindle送人了。
既然花巨款了,就想固定一下漫画来源渠道。
我收藏的漫画网站
第一个网站被墙了,我也尝试反向代理过但好像有个反爬机制,反代以后漫画就加载不出来了,很是头疼。
第二个网站可以看,但是不能直接下载。
我就上github查了一下,发现真有人做了爬虫爬漫画,我就拿过来用了
项目地址copymanga-downloader
虽说是能下了,但对于连载中的漫画,还是很麻烦。
总不能每次更新都要去自己下漫画,然后再让kindle接入电脑拷贝进去吧
于是我决定用爱发电给主项目交一个pull request,让他支持更新以后自动推送到kindle。
思路
- 利用他的项目监控漫画
- 将追的漫画记录到本地,然后比较本地数据,如果有新漫画则执行下面步骤,否则返回1
- 调用kcc(Kindle Comic Converter)将下载下来的jpg文件转换成kindle支持的
mobi格式
- 调用邮件接口发送邮件
嗯,这样看还是挺简单的,但很有问题。
比如步骤1和2,他的登录方式是从网页上把token拿下来,然后再下载,这样做的缺点在于,你无法实现长期长时间登录,这也是作者所不希望的,因为本来网站就是用爱发电,平白无故占用别人网站资源等于做坏事。
步骤3,kcc是一个带ui的一个exe程序,不知道支不支持命令行调用或者接口调用的方式
步骤4倒是很简单
嘛船到桥头必有路。
过程
先解决步骤1和2的问题,打开 charles抓包看看登录
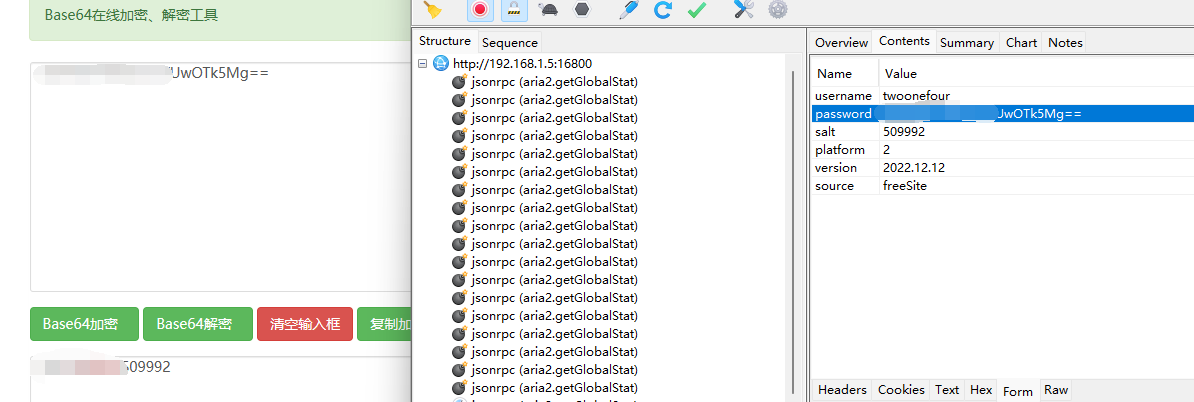
有点太过于简单了不知道说什么
这个password一眼看过去就是 base64加密,下面有个 salt,直接base64反解密得到password明文组成格式如下
password-salt
现在找找这个 salt怎么来的,直接在 charles上 ctrl+F搜索——可惜没找到
我的直觉是随意6个数字,发给后端就行
那么直接能写出如下代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
def login(**information: {"username": None, "password": None, "url": None, "salt": None}):
if information["username"]:
try:
res = requests.post(f"https://{information['url']}/api/kb/web/login", data={
"username": information["username"],
"password": information["password"],
"salt": information["salt"]
}, headers={
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0"
})
res_json = res.json()
if res_json["code"] == 200:
return res_json["results"]["token"]
else:
print(res_json["message"])
except Exception as e:
return None
return None
|
他的写法本来是一个token的,只要把获得到的token回传就能正常运行了,再加个自己输入代码的流程
主要逻辑如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
|
## 在主函数中调用login做一个封装
def loginhelper(username, password, url):
import login
from random import randint
from base64 import b64encode
salt = randint(100000, 999999)
password_enc = password + f"-{salt}"
password_enc = b64encode(password_enc.encode()).decode()
res = login.login(**{"username": username, "password": password_enc, "url": url, "salt": salt})
return {"token": res, "salt": salt, "password_enc": password_enc}
def loginInformationBuilder(username, password, url, salt):
return {"username": username, "password": password, "url": url, "salt": salt}
## 修改保存设置的地方
def set_settings():
loginPattern = Prompt.ask("请输入登陆方式(1为token登录,2为账号密码持久登录)", default="2") # 添加loginPattern,判断登陆模式以接入我写的登陆模式
if loginPattern == "1":
authorization = Prompt.ask("请输入token")
if loginPattern == "2":
# 我写的模式
while True:
username = Prompt.ask("请输入账号").strip()
password = Prompt.ask("请输入密码").strip()
if username == "" or password == "":
print("请输入账号密码")
continue
else:
res = loginhelper(username, password, api_urls[choice - 1])
if res["token"]:
authorization = f"Token {res['token']}"
salt = res["salt"]
password = res["password_enc"]
break
settings = {
"download_path": download_path,
"authorization": authorization,
"use_oversea_cdn": use_oversea_cdn,
"use_webp": use_webp,
"proxies": proxy,
"api_url": api_urls[choice - 1],
"HC": hc,
"CBZ": cbz,
"cbz_path": cbz_path,
"api_time": 0.0,
"API_COUNTER": 0,
"loginPattern": loginPattern, # 添加登陆模式,下面同此行
"salt": salt if loginPattern == "2" else None,
"username": username if loginPattern == "2" else None,
"password": password if loginPattern == "2" else None
}
## 修改token过期后读取设置的地方,只列出关键的修改点
if data['code'] == 401:
settings_dir = os.path.join(os.path.expanduser("~"), ".copymanga-downloader/settings.json")
if SETTINGS["loginPattern"] == "1":
print(f"[bold red]请求出现问题!疑似Token问题![{data['message']}][/]")
print(f"[bold red]请删除{settings_dir}来重新设置!(或者也可以自行修改配置文件)[/]")
sys.exit()
else:
import login
res = login.login(**loginInformationBuilder(SETTINGS["username"], SETTINGS["password"], SETTINGS["api_url"]))
if res:
API_HEADER['authorization'] = res
continue
time.sleep(2 ** retry_count) # 重试时间指数
retry_count += 1
|
今天就写到这吧,看别人代码加上躺在床上写,头很疼,明天可以考虑给他自己写一个单独的模块,然后调用他的函数
(2024.01.14更新)
关于步骤2,偶然发现他已经写了一个叫半自动更新的功能,会将漫画记录集数存到本地,我这里就直接拿来用啦,步骤二直接跳过
步骤3,可以将kcc命令行版本下载到本地,有命令行命令,直接在python环境中调用,于是步骤3也解决了
步骤4很简单,直接略
本来自己用的时候,一个小时很简单的写好了,但考虑到我要提交代码,于是写了比较长时间
