前言
最近一直使用异世界动漫这个网站下载动画资源,他长这样
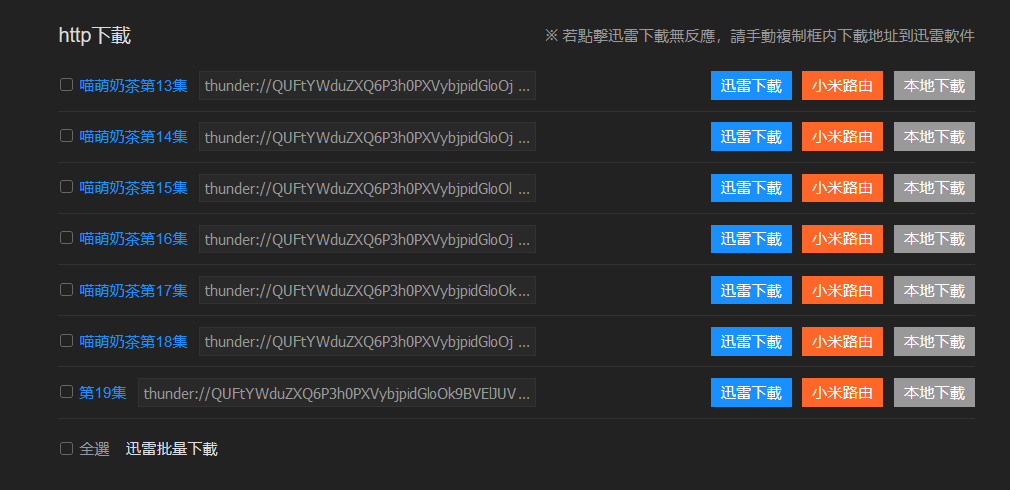 实际上我要用的是本地下载的连接,默认是迅雷的链接,我要把他下到我的nas上,nas使用docker封装的qBittorrent
实际上我要用的是本地下载的连接,默认是迅雷的链接,我要把他下到我的nas上,nas使用docker封装的qBittorrent
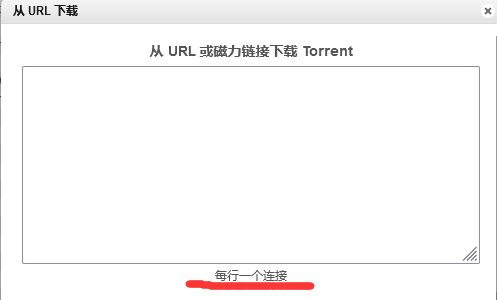 每行一个链接
要一个个点复制链接
每行一个链接
要一个个点复制链接
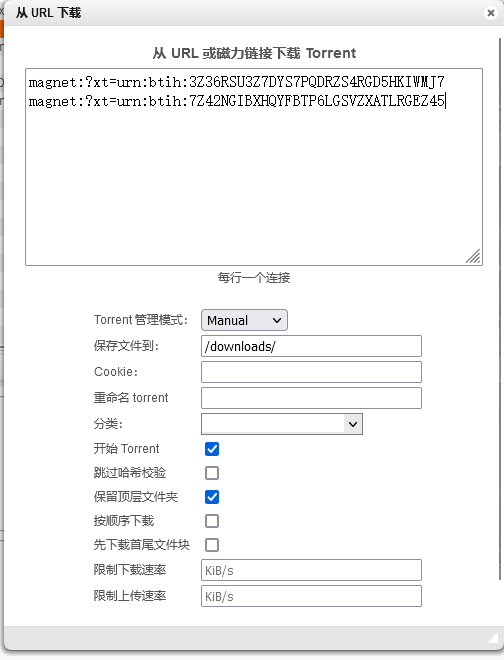
 最后变成这样下载
最后变成这样下载
太(省略脏话)麻烦了,作为一个爬虫起家的,我不能接受这么麻烦的操作
于是就有了本篇文章
思路
找xpath
先打开要爬的网站
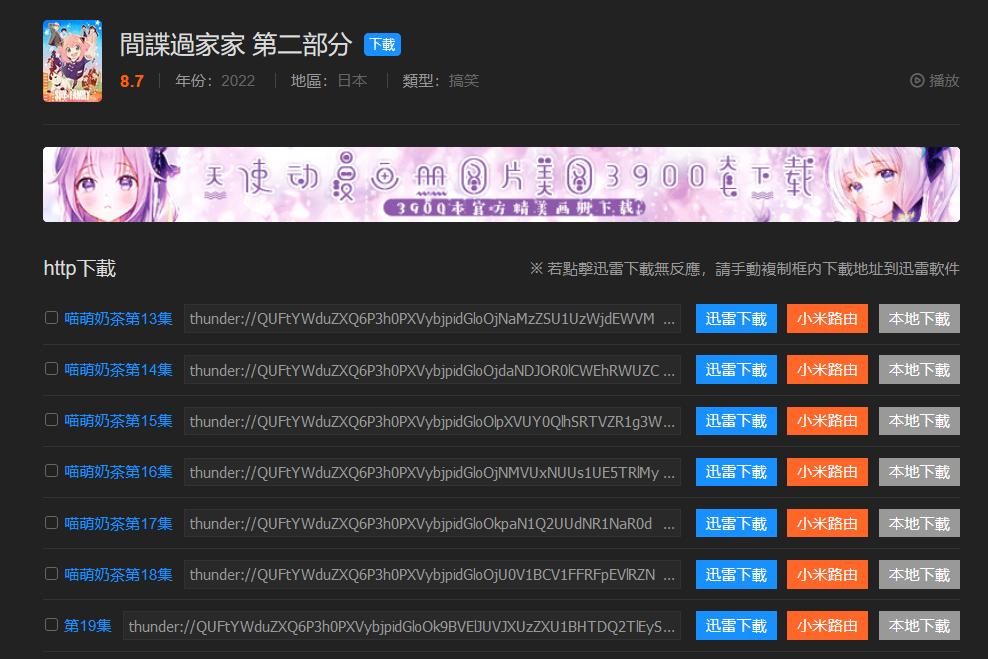 翻到这一部分,按f12,点元素选择器
翻到这一部分,按f12,点元素选择器
 把鼠标放到本地下载上
把鼠标放到本地下载上
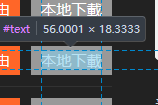 元素就出来啦
元素就出来啦
 a标签的href就是我们所需要的磁力链接
右键这条,复制,Xpath
a标签的href就是我们所需要的磁力链接
右键这条,复制,Xpath
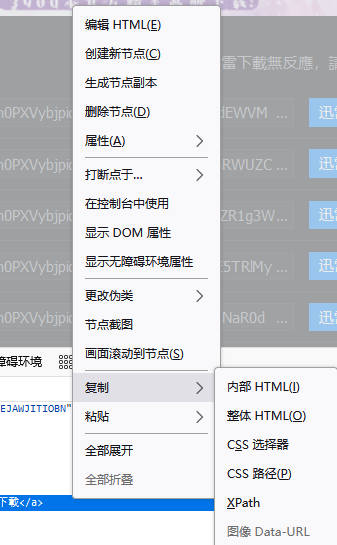 我这里得到的是
我这里得到的是
1
|
/html/body/div[2]/div[2]/div[3]/div/div[2]/ul/li[4]/span/a
|
很明显,li[4]这里的4改变就可以遍历所有的磁力链接了
selenium实现
1
2
3
4
5
6
7
8
9
10
11
12
|
browser = webdriver.Firefox()
websiteURL = input("请输入要爬取的网址:")
browser.get(websiteURL)
# wait = WebDriverWait(browser,30,0.5)
# wait.until(lambda diver:browser.find_element(By.XPATH,'/html/body/div[2]/div[2]/div[3]/div/div[2]/ul/li[1]/span/a'))
for i in range(1,100):
try:
print(browser.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[3]/div/div[2]/ul/li[{}]/span/a'.format(i)).get_attribute("href"))
except Exception as e:
break
browser.close()
|
这里比较重要的是get_attribute()方法,把href作为参数传入方法就能找到元素了,最后结果如下
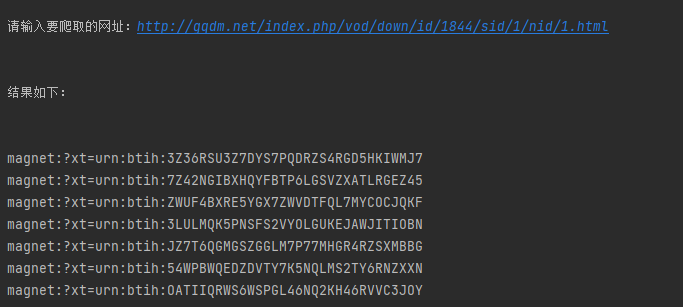
requests库实现
requests需要解析一下html文件,我用的是lxml.etree
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
session = requests.session()
websiteURL = input("请输入要爬取的网址:")
print("") # 美化一下输出格式,方便复制磁力链
print("")
res = session.get(websiteURL)
parser = etree.HTMLParser(encoding="utf-8")
tree = etree.HTML(res.text)
print("结果如下:")
print("")
for i in range(1,100):
try:
print(dict(tree.xpath("/html/body/div[2]/div[2]/div[3]/div/div[2]/ul/li[{}]/span/a".format(i))[0].attrib)["href"])
except Exception as e:
break
break
print("")
print("")
|
最终效果同selenium
最终代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
import urllib3
import requests
from lxml import etree
urllib3.disable_warnings()
while True:
pattern = input("请输入模式(1代表使用selenium,2代表使用requests):")
print("")
if pattern == "1":
browser = webdriver.Firefox()
websiteURL = input("请输入要爬取的网址:")
browser.get(websiteURL)
# wait = WebDriverWait(browser,30,0.5)
# wait.until(lambda diver:browser.find_element(By.XPATH,'/html/body/div[2]/div[2]/div[3]/div/div[2]/ul/li[1]/span/a'))
for i in range(1,100):
try:
print(browser.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[3]/div/div[2]/ul/li[{}]/span/a'.format(i)).get_attribute("href"))
except Exception as e:
break
browser.close()
break
elif pattern == "2":
session = requests.session()
websiteURL = input("请输入要爬取的网址:")
print("")
print("")
res = session.get(websiteURL)
parser = etree.HTMLParser(encoding="utf-8")
tree = etree.HTML(res.text)
print("结果如下:")
print("")
for i in range(1,100):
try:
print(dict(tree.xpath("/html/body/div[2]/div[2]/div[3]/div/div[2]/ul/li[{}]/span/a".format(i))[0].attrib)["href"])
except Exception as e:
break
break
print("")
print("")
else:
print("输入错误,请重新输入")
|
测试效果
选个大伙最爱的电锯人测试一下
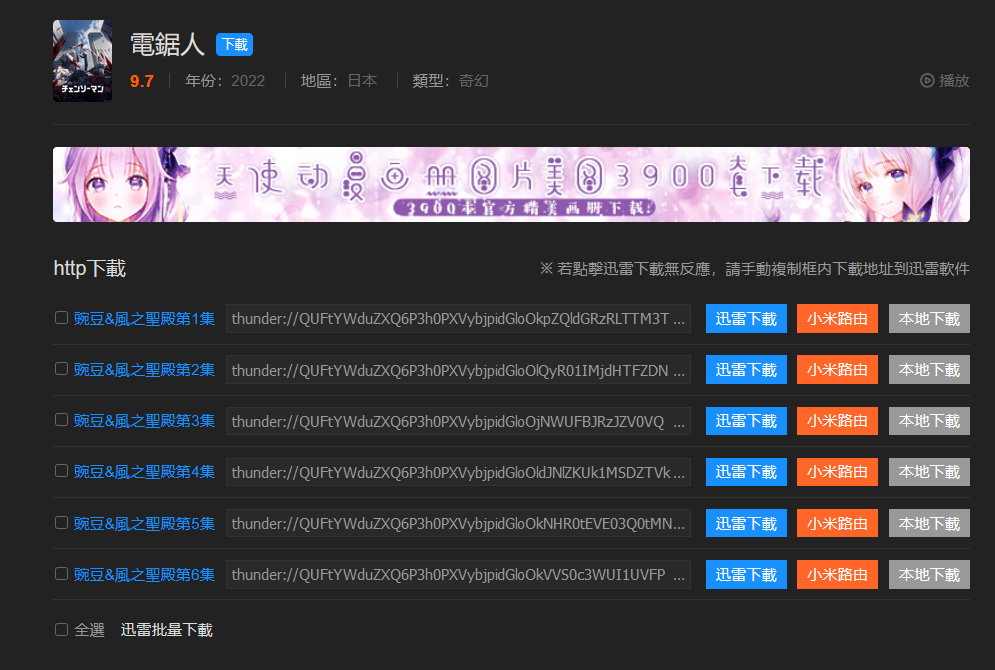
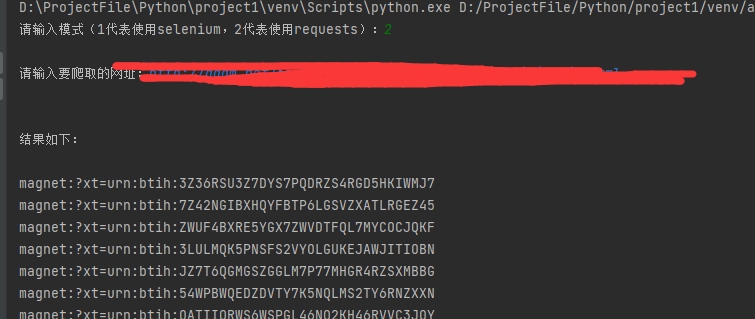
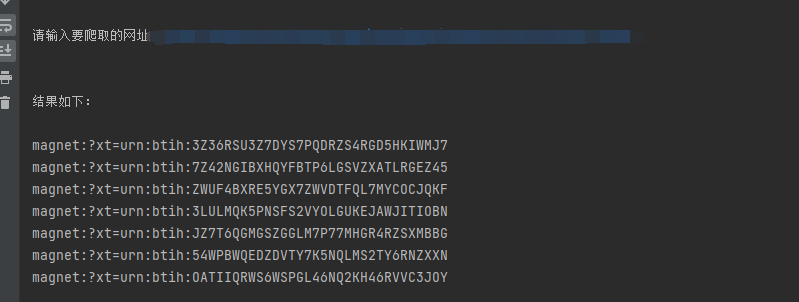
看开头比对,明显对上了,ok下班咯

后记
最近我的宝贝看了我写的博客,说为什么我的日记没有她,她好可爱。我很想跟她解释这是技术博客不是日记。有关宝贝的被我存在备忘录里了,只能被我自己看到,不会写在技术博客里给别人看的啦